
意思決定の「スピードと質」向上のためのIT活用
サマリー
ITを活用して意思決定の「スピードと質」を向上させるためには、「情報を比べ易い構造で保存」している必要があります。その構造を考える手段として、ER図の活用をおすすめします。

中山 宗
中小企業診断士 / ThinkHelper合同会社 代表社員
日系企業と外資系企業にてシステムエンジニアおよびITコンサルタントとして従事すると共に、海外支社の立ち上げを経験。現在は、ITを活用した意思決定と業務改善の支援(社外CIO)を主に行っている。趣味は、道東の「美味しい食べ物」と「綺麗な景色」探し。
目次
はじめに
大企業では、組織の意思決定にITを活用することが当たり前になっています。一方、その他の組織では、IT活用が「情報のデジタル化」や「業務の自動化」に止まっており、意思決定で十分活用できていない印象です。
どのような取り組みでも、その取り組みを始める前に、必ず「やる」または「やらない」という意思決定を行っています。(「何もしない」というのは、『やらない』という意思決定と同じです。)そして、その意思決定の結果が「成果」となるため、意思決定の「スピードと質」を向上させると、「成果が出るまでの期間短縮」や「成果の質向上」が期待できます。
本投稿では、ITコンサルタントおよびシステムエンジニアとして働いていた経験を元に、意思決定の「スピードと質」を向上させるためのIT活用方法と、それを可能にする情報の保存方法について概要を説明します。
意思決定とITの関係
最初に、なぜIT活用が意思決定の「スピードと質」向上に繋がるのかを説明します。
意思決定の大まかな流れ
世の中の変化が激しく、他の真似をしても成果が出ない今、「意思決定による成果を見て、再び意思決定をする」というサイクル(以下「意思決定のサイクル」と記載)を回し、良い成果が出る取り組みを「探している」と思います。大まかに書くと、以下のプロセス1〜6を繰り返しているのではないでしょうか。
- 現時点で分かっている情報から取り組み内容を考える
- 考えた取り組み内容の実行結果について予想する
- 「考えた取り組み内容を実行する」決断をする
- 実際に、考えた取り組み内容を実行する
- 「実行前の予想」と「実際の結果」を比べる
- 「実行前の予想」と「実際の結果」の違いを生む原因について考える
意思決定の「スピードと質」向上
意思決定を「良い成果が出る取り組みを探し出す活動」と捉えた場合、その性質上、試行錯誤は避けられません。そして、これは全ての組織に言えることです。
そのため、1回の試行錯誤に必要な時間を減らす一方、試行錯誤の回数を増やし多くを学び、その学びから予め「良い成果が出ない可能性の高い取り組み」を排除できるようになれば、同じ期間内で、他の組織より早く「良い成果が出る(結果的に「良い意思決定」といえる)取り組み」を見つけることができます。
つまり、「1回の試行錯誤に必要な時間」を減らすことを『意思決定のスピード向上』、予め「良い成果が出ない可能性の高い取り組み」を排除できることを『意思決定の質向上』と言えるのではないでしょうか。
意思決定の「スピード向上」とITの関係
ITを活用することで、先述した「意思決定のサイクル」のプロセス2「考えた取り組み内容の実行結果について予想する」と、プロセス5「実行前の予想と実際の結果を比べる」に要する時間を短縮化でき、結果的に、1回の試行錯誤に必要な時間を減らすことが可能です。
まず、プロセス2「考えた取り組み内容の実行結果について予想する」の時間短縮ですが、「予想に必要な情報を速やかに収集」し、「その情報を掛け合わせる等して複数の予想を速やかに作る」必要があります。ITを使わなくても実施可能ですが、ITを活用できた方が短時間で終わることは納得頂けるかと思います。
次に、プロセス5「実行前の予想と実際の結果を比べる」の時間短縮ですが、「予想で用いた情報を速やかに収集」すると共に、「取り組み過程で発生した情報を速やかに収集」し、「収集した情報同士を比べて速やかに違いを明らかにする」必要があります。こちらの作業についても、ITを使わず実施可能ですが、ITを活用できた方が短時間で終わることは納得頂けるかと思います。
意思決定の「質向上」とITの関係
ITを活用し意思決定のスピードが向上すると、同じ時間内で、先述した「意思決定のサイクル」を他の組織よりも数多く回せるようになります。
その結果、プロセス6の「実行前の予想と実際の結果の違いを生む原因について考える」機会が増え、組織としての学びが蓄積されます。この蓄積により、プロセス1「現時点で分かっている情報から取り組み内容を考える」を行う際、予め「良い成果が出ない可能性の高い取り組み」を排除できる機会が増え、無駄な「意思決定のサイクル」を回す可能性が減ります。
また、組織的な学びが蓄積されることによって、プロセス2「考えた取り組み内容の実行結果について予想する」の精度が向上し、それにつられプロセス5「実行前の予想と実際の結果を比べる」の精度も向上します。
そして、プロセス5「実行前の予想と実際の結果を比べる」の精度が向上した結果、新たな気付きを得られるため、プロセス6の「実行前の予想と実際の結果の違いを生む原因について考える」の質が向上するという好循環が生まれます。
多くの組織で見る問題点
先述の「意思決定とITの関係」から、意思決定の「スピードと質」を向上させるためのIT活用方法を抽出すると、下記の3つになります。
- 「予想に必要な情報」や「取り組み過程で発生した情報」を速やかに収集する。
- 収集した「予想に必要な情報」や「取り組み過程で発生した情報」を比べ、速やかに違いを明らかにする。
- 収集した「予想に必要な情報」を掛け合わせる等して、複数の予想を速やかに作る。
方法3の「収集した予想に必要な情報を掛け合わせる等して、複数の予想を速やかに作る。」については、予想に必要な「計算式を作る技術」がITとは別に必要になるため、これ以降は、方法1と方法2のみを扱います。
方法1の本質は、「必要な情報を速やかに収集する」ことです。一方、方法2の本質は、「収集した情報同士を速やかに比較する」ことです。つまり、「速やかに必要な情報を収集して比較する」ことができれば、ITを活用した意思決定の「スピードと質」の向上が可能になるということです。
その点を踏まえた上で、多くの組織で見る問題点について説明します。
PCに入力しているだけ
紙に印刷するために、PCやタブレット等で情報を入力している状態です。
PC等の使い方が、ワープロ時代と同じだと発生します。PC等で情報を入力したにも関わらず、情報の保管は、紙に印刷してキングファイルで綴じているということはないでしょうか。(原本保管を法的に求められる書類は除きます。)
この状態では、探したい情報を目視で探さなければならず、速やかに情報を収集できません。また、情報収集後も、情報を比較するために再度PC等に入力を行う必要があり、速やかに比較が行えません。
情報の鮮度がバラバラ
デジタル化して情報が探し易くなっているように見えるものの、情報の鮮度がバラバラという状態です。
組織全体を見ず、部分最適でIT導入を進めると発生します。同じ人についての情報を閲覧しているにも関わらず、部署によって住所が異なっているということはないでしょうか。
この状態では、速やかに正しい(最新の)情報を収集できません。逆に、誤った(古い)情報を収集して比較し、誤った意思決定をしてしまうリスクがあります。
意思決定に必要な情報の抽出が大変
デジタル化により情報が探し易く、情報の鮮度も揃っているものの、意思決定に必要な情報の抽出が大変という状態です。
ITシステム導入を組織外に丸投げした時に発生します。部署間で最新の情報や変更履歴が見られるようになっているものの、「現場の状況を把握する指標」や「管理会計」が考慮されておらず、意思決定に必要な情報をITシステムから抽出しExcelで集計しているということはないでしょうか。
この状態も、速やかに必要な情報を収集できません。また、必要な情報が速やかに収集できない以上、情報同士の比較も速やかに行えません。
以上より、「速やかに必要な情報を収集して比較する」ことを可能にするためには、組織外への他力本願は止め、組織内で主体的かつ全体最適の視点から「情報を保存する構造」について考える必要があります。
ただし、最初から全て組織内で行うことは難しいため、必要な箇所のみ社外の専門家にサポートしてもらい、組織内に「情報を比べ易い構造で保存する設計技術(考え方)」を蓄積するという進め方が安全かと思います。
情報を保存する構造の考え方(簡易版)
「速やかに必要な情報を収集して比較する」ことを可能にするためには、「情報を比べ易い構造で保存」している必要があります。その構造を考える手段として、ER図の活用をおすすめします。
ER図は、ITコンサルタントやシステムエンジニアが主に作成しますが、ITに関する専門知識は必要ありません。また、計算もしません。理屈さえ分かれば中学生でも考えられる内容のため、是非、気軽にお試しください。
ここでは例として、美容室を扱います。なお、説明を簡潔にするために、一部の情報しか扱っておりませんが、その点についてはご容赦ください。
手順1:保存する情報を洗い出す
最初に、保存する情報を洗い出し、「日々変わるもの」と「基本的に変わらないもの」に分けます。基本的に変わらない情報は、「マスター」と呼ばれたりします。以下、洗い出しの例です。
- 日々変わる情報
- 来店した顧客、来店日、来店時に提供したサービス
- 担当した従業員、接客開始時刻、接客終了時刻、接客時間分の人件費
- 基本的に変わらない情報
- 顧客の名前、顧客の生年月日、顧客の性別、顧客の初回来店日、紹介元の顧客
- 従業員の名前、従業員の生年月日、従業員の性別、従業員の人件費
- サービスの名前、サービスの販売価格
手順2:情報の保存形式を決める
次に、洗い出した各情報を数字、日時、選択肢、文字列のどの形式で保存するかを決めます。ここでポイントになるのが、基本的に集計可能なのは「数字、日時、選択肢」だけです。
近年、文字列についても分析可能になってきていますが応用編にあたるため、まずは「情報を比べ易い構造で保存する設計技術(考え方)」の理解を優先して頂いた方が良いかと思います。以下、保存形式の例です。
- 日々変わる情報
- 来店した顧客【選択】、来店日【日時】、来店時に提供したサービス【選択】
- 担当した従業員【選択】、接客開始時刻【日時】、接客終了時刻【日時】、接客時間分の人件費【数字】
- 基本的に変わらない情報
- 顧客の名前【文字列】、顧客の生年月日【日時】、顧客の性別【選択】、顧客の初回来店日【日時】、紹介元の顧客【選択】
- 従業員の名前【文字列】、従業員の生年月日【日時】、従業員の性別【選択】、従業員の人件費【数字】
- サービスの名前【文字列】、サービスの販売価格【数字】
手順3:情報同士の関係性を考える
最後に、分析(情報を比べる)方法を意識しながら、情報同士の「まとまり」や「繋がり」を考え、これまでバラバラに考えていた情報をグルーピングし、情報同士の繋がりを作っていきます。その際、情報同士を比較し、どのような洞察を得たいのか(案件別の粗利を把握して、収益改善のヒントにしたい等)も合わせて考えてください。
なお、本投稿では、ER図作成の全体的なイメージを持って頂くことを主要目的にしています。ER図の詳細な作成方法が気になる方は、関連する書籍やWebページをご覧ください。
最初のステップは、バラバラに考えていた情報をまとめます。作業結果を「紙に印刷した表」に例えると、個別の用紙に「従業員マスター」や「稼働時間」といった表が1つだけ描かれていて、「従業員マスター」の表には、「従業員No」や「従業員の名前」という列が存在するイメージです。今後、この表(情報をまとめた塊)のことを『テーブル』と記載します。
また、次のステップで情報同士の繋がりを作るために、各テーブルへ「No」という「テーブル内で重複しない情報」を追加しています。以下が上記の作業を行った結果です。
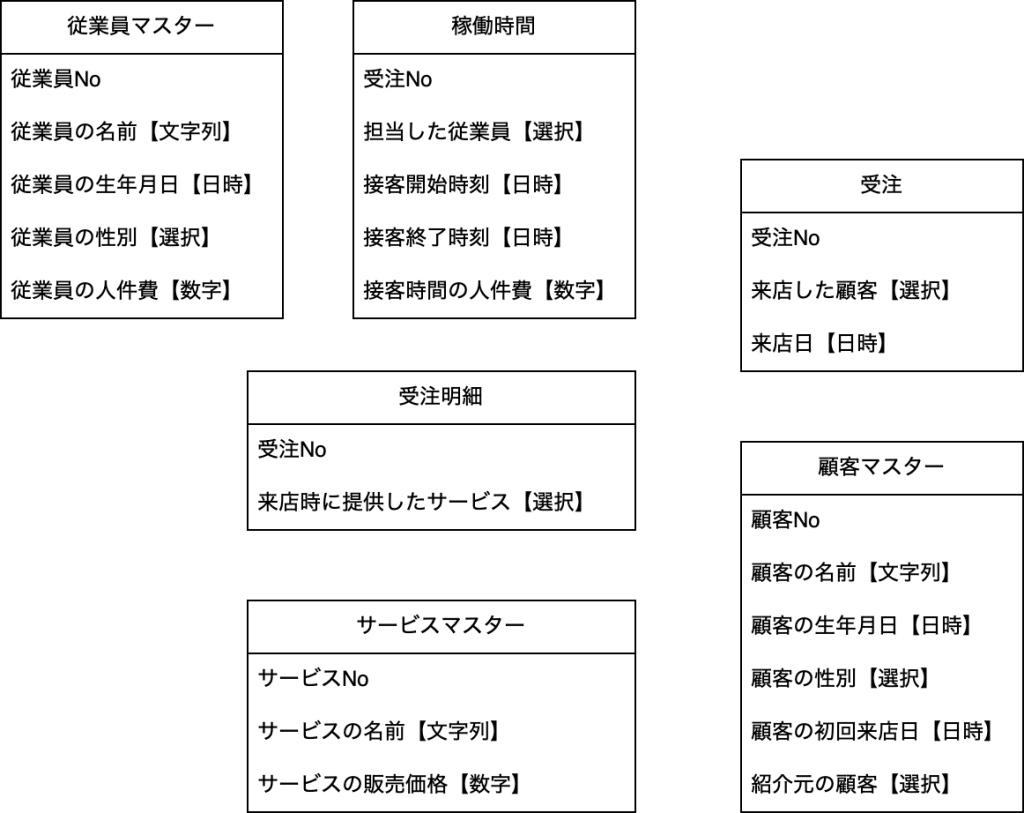
次に、情報同士の繋がりを考えます。こちらは、先に図を見てください。
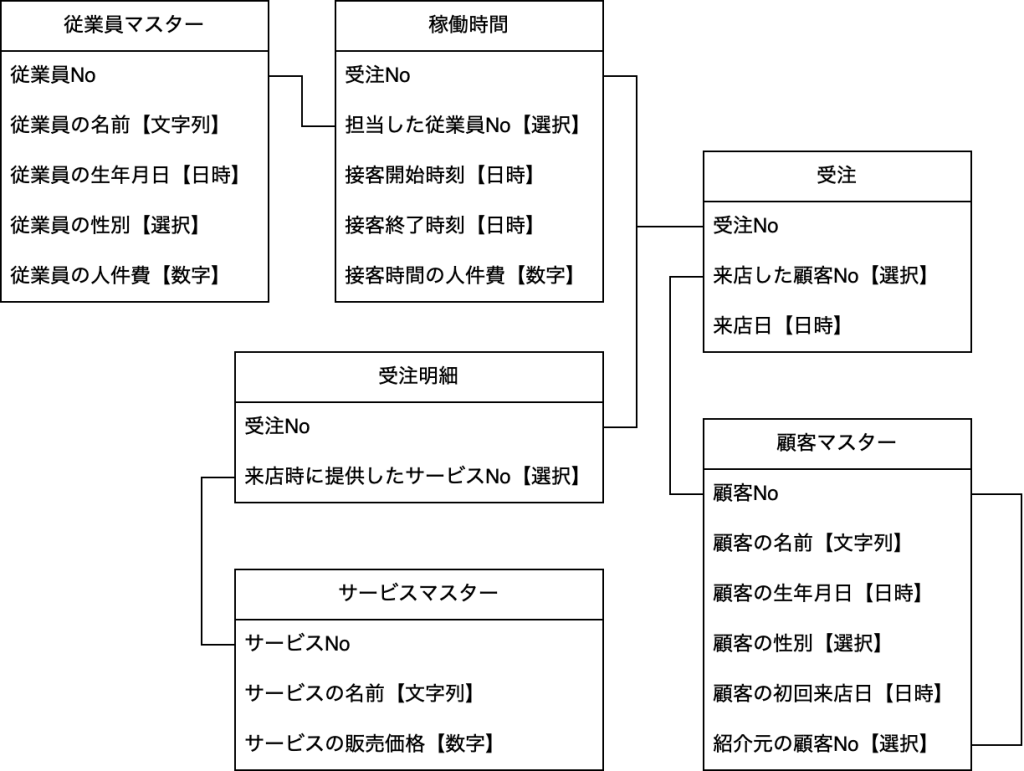
「受注」テーブル内にあった「来店した顧客【選択】」を「来店した顧客No【選択】」に変更しています。この作業によって、「受注」テーブルと「顧客マスター」テーブルを紐付けています。また、同様の処理を他のテーブルでも行っています。
なお、「来店した顧客No」に変更後も保存形式が『選択』のままですが、「来店した顧客No」に入力可能な情報は、「顧客マスター」テーブルに存在する『顧客No』だけであるため、『選択』のままで問題ありません。
また、「稼働時間」テーブルに存在する『接客時間の人件費』は、「従業員マスター」の『従業員の人件費【数字】』と「稼働時間」テーブルの『接客開始時刻【日時】』および『接客終了時刻【日時】』から計算して保存する作りとしています。
以上で、「情報を比べ易い構造で保存」する器が完成しましたが、具体例があった方が理解度も深まると思いますので、情報を保存した時の図を下記に掲載します。
具体例:注文別の粗利算出
- 顧客No「C02468」からの紹介で
- 2018年3月4日に初来店した顧客「北海 道子」さんが
- 2022年12月26日に来店し
- 美容室の従業員である「札幌 太郎」さんに
- 10時から12時30分の間で
- 4千円のヘアカットと6千円のヘアカラーをしてもらいました。
- 従業員「札幌 太郎」さんの人件費が月額32万円のため
- 接客時間分の人件費は5千円で
- カラーリングの仕入価格を無視した場合
- 粗利は5千円( = 4千円 + 6千円 – 5千円)になりました。
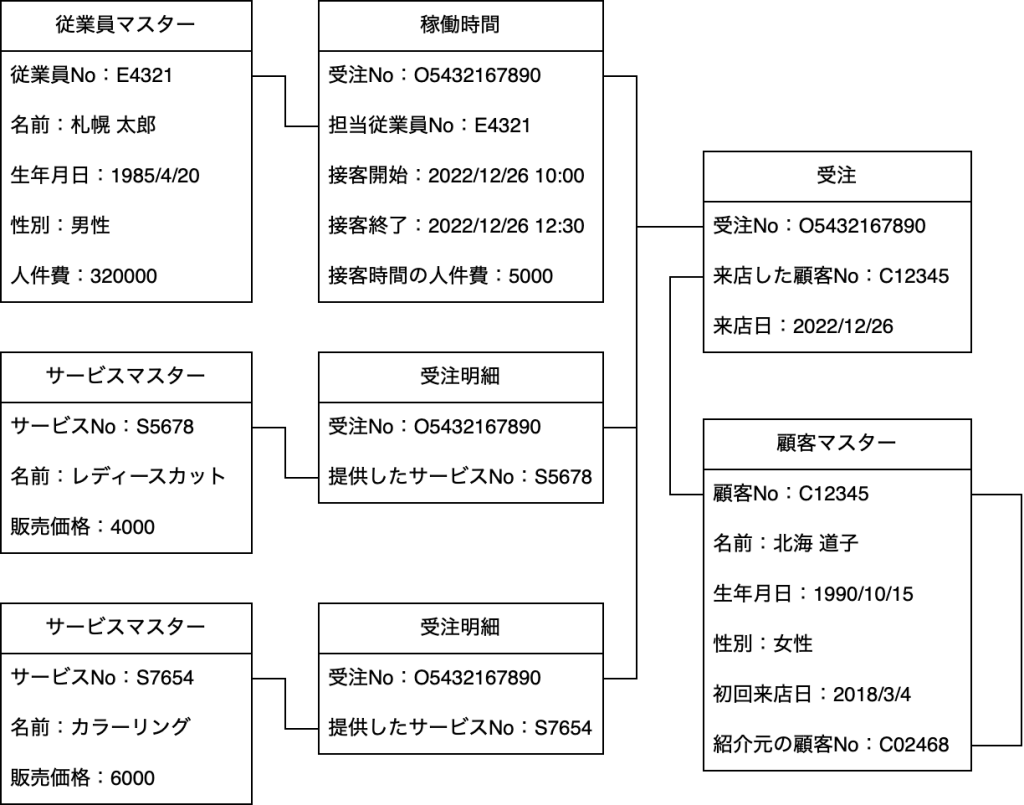
いかがでしょうか。情報が各テーブルに分散して保存されています。また、保存された情報同士は、「No」を介して繋がっています。
情報を比べ易い構造で保存する効果
これまでの説明だけでは、情報が分散して保存されるだけで、何もメリットが無いと思えるのではないでしょうか。
ここからは、ER図を使って「情報を保存する構造」を考える効果について説明します。
情報の重複保存を防止
例えば、「2022年に来店した30代女性の内、カラーリングを注文した人数を月次で知りたい」場合、表にすると「来店日、顧客名、生年月日、性別、提供したサービス」の5列があれば集計可能ですが、下記のような「情報が重複する表」を作成しなければなりません。
| 来店日 | 顧客名 | 生年月日 | 性別 | 提供したサービス |
| 2022/1/18 | 北海 道子 | 1990/10/15 | 女性 | ヘアカット |
| 2022/1/18 | 北海 道子 | 1990/10/15 | 女性 | ヘアカラー |
| 2022/2/14 | 北海 道子 | 1990/10/15 | 女性 | ヘアカット |
| 2022/2/14 | 北海 道子 | 1990/10/15 | 女性 | 縮毛矯正 |
ER図で考えた「情報を保存する構造」であれば、「北海 道子」さんが何回来店しても「顧客マスター」テーブルの情報は増えません。情報が増えるのは、「受注」テーブルと「受注明細」テーブルだけです。
情報収集のし易さ
情報が重複しない1つの表で「2022年に来店した30代女性の内、カラーリングを注文した人数を月次で集計」することは不可能です。
一方、情報を各テーブルに分散して保存した場合、情報収集は以下の流れ(ステップ)になります。
- 「顧客マスター」テーブルから、30代女性の『顧客No』のみを抽出
- 「受注」テーブルから、ステップ1で抽出した「顧客No」を含む『受注No』と『来店日』を抽出
- 「受注明細」テーブルから、「提供したサービスNo」がカラーリングである『受注No』のみを抽出
- ステップ2で抽出した情報の内、「ステップ3で抽出した『受注No』と一致する情報」を抽出
- ステップ4で抽出した「受注」テーブルの情報を「来店月」ごとにグルーピング
- ステップ5でグルーピングした各月ごとの「情報の個数(つまり人数)」を数える
各ステップで情報の抽出を繰り返し、情報が絞り込まれていく(収集したいと考えている情報だけ残っていく)イメージをお持ち頂けたでしょうか。
この情報収集方法は、保存された情報同士を繋ぐ「No」によって実現しており、テーブルが100個あっても200個あっても情報を絞り込むことが可能です。
情報同士の比較し易さ
ER図で考えた「情報を保存する構造」の場合、各テーブルに保存される「内容」と「保存形式(数字、日時、選択肢、文字列)」は、比較することを前提に検討済みです。そのため、保存形式が異なり比較できないという状況は希だと思います。
また、説明を簡潔にするため本投稿に記載していませんが、各テーブルの「内容」ごとに情報入力を『必須』か『任意』か決めることで、「情報同士を比較したいのに、情報が入力されていない」という状況も回避できます。
そして、ER図で考えた「情報を保存する構造」は、データ分析用サービス(Amazon QuickSightやMicrosoft Power BI等)との相性も良く、データ分析用サービスへのデータ投入もスムーズに行えます。
おわりに
ER図が完成した後は「情報共有のし易さ」や「分析結果の見易さ」を考慮し、Excel、kintone、その他クラウドサービス等の中から情報の保存先を決め、ER図に沿って作り込んでいくことになります。
ER図を見れば、組織として「速やかに収集と比較が可能な情報」が一目瞭然です。その結果、意思決定に必要な情報が不足している場合、追加情報として何を取得する必要があるのか議論もし易くなります。
ER図というITコンサルタントやシステムエンジニアが使う技術ではありますが、この技術が意思決定の「スピードと質」を向上させるヒントになれば幸いです。